
Stakeholder Dynamics in Data Modeling
From Part 2 - How Politics and Power Influence Data Models

In the full-contact sport of data modeling, you are never working in isolation. Your success depends on your ability to navigate a complex web of people with competing interests, needs, and levels of influence. These are your stakeholders. Identifying them isn't just good practice. It's the first step in mapping the political terrain, which we’ll dive into shortly.
Internal vs. External Stakeholders
We all have stakeholders, those individuals or groups that have a "stake" in some part of an organization’s success. This could be the success of a new initiative, the launch of a new product, or a boost in the share price. In data modeling, you’ll encounter two main types of stakeholders: internal and external. Let’s examine these and their impact on data modeling.
Internal stakeholders are individuals or groups that are directly involved in the company’s operations and have a vested interest in its success. They are typically found within the organization and include employees, management and executives, the board of directors, and shareholders and investors.
The data model you provide for internal stakeholders will be used within the company. It might be an application that powers a part of the business, a report used by executives, or an ML model powering a business process. These use cases may not directly impact end customers, but they help streamline business operations. Here, the data model must influence trust inside the company.
External stakeholders are individuals or groups outside the organization that are indirectly affected by the company's actions and decisions, including customers, suppliers, governments, and the broader community impacted by the organization. Here, the stakes often involve compliance, contractual obligations, and brand reputation.
For instance, I have many friends who work in the financial industry, which is heavily regulated. Here, their data must be modeled to produce the exact data required to meet regulations and expectations of various other external stakeholders (investors, boards, etc). Providing an “almost good” answer isn’t going to work and might result in fines or jail. The stakes are clearly understood, and the data is modeled accordingly.
In another example, regulations like GDPR clearly state you must delete a user’s data upon request. How will you do this? It’s incredible how many data models don’t allow for an easy, cascaded deletion of data, forcing manual deletion instead. Given the risk of “missing something” in this case, proper attention to modeling is imperative.
Bottom line - clearly know the risks associated that your model imposes on your internal and external stakeholders.
The Power Interest Grid
Before we look at the major stakeholder groups you’ll meet, let’s quickly lay out a classic framework for stakeholder management - the Power Interest Grid. This gives you a rubric for understanding who to keep happy and who you don’t need to invest as much time with.
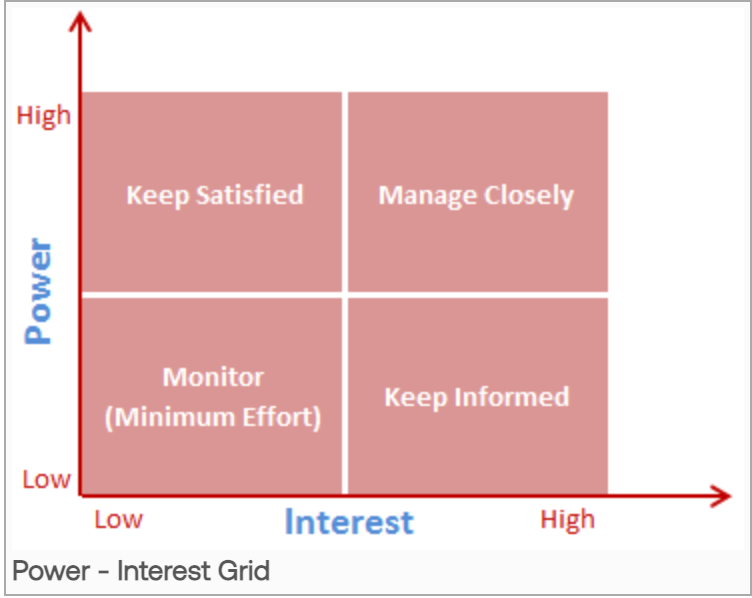
Here are the four buckets to pay attention to:
High Power, High Interest (Key Players - Manage Closely): These are the people you must fully engage and manage closely (e.g., your executive sponsor, the lead developer of the app using your model).
High Power, Low Interest (Keep Satisfied): These are people who can kill your project but don't care about the details (e.g., a CFO who only sees the budget line). Give them the executive summary.
Low Power, High Interest (Keep Informed): These are often your end-users or allies who are passionate but lack influence (e.g., the analyst who will use the data). They are a great source of feedback.
Low Power, Low Interest (Monitor - Minimum Effort): This is your "Everyone Else" category, which you’ll learn about shortly.
As you learn about the four stakeholder groups, keep in mind where they fit into the Power Interest grid. The groupings will vary on the situation, and realistically, don’t map neatly (except the “Everyone Else” group). The reason is that you might have a High Power, High Interest stakeholder who might be an internal or external consumer, or might be part of the Support Crew. Use this guide to map the terrain of your working relationships and determine how much you’ll need to serve them.
The Four Stakeholder Groups You'll Work With
Your stakeholders will view your data models in different ways. Some will be directly involved in it, while others will be tangentially impacted, and still others will be unaware of what data modeling is or who you are.
In data modeling, consider stakeholders from four complementary lenses: internal and external consumers, supporters, and everyone else. These stakeholders are presented in terms of those you’ll impact most to those least affected by your work. Let’s look at the first two types of consumers, internal and external.
Internal Consumers
Most of the time, internal consumers are your co-workers and bosses. They utilize your data model to perform their tasks and help the business move forward. The data they use to do their jobs is the nervous system of the company.
Some typical internal consumers of data are:
Executives require data to inform their decisions and actions. Often, executives need to make quick decisions in situations of uncertainty. The data you provide should be analyzed for KPI dashboards and strategic summaries.
Operational and line-of-business staff who rely on timely, accurate data to keep day-to-day processes running. These might be people in the supply chain, marketing, or accounting who all rely on good quality data to do their jobs. They might also be the people who impact your data by manually inputting data. This is often the classic feedback loop in data - garbage in, garbage out, or oppositely, quality in, quality out. Furthermore, this same data might be used to power apps, analytics, or ML models used by other internal and external consumers.
Developers who both create and rely on data to keep applications running. Applications are a feedback loop where data is generated, processed, and saved either in an updated form or as a new piece of data. Central to all this is a robot data model that powers the application.
Analysts and data scientists require flexible, well-structured data to conduct in-depth analyses and experiments on various business questions. The quality of analysis and experiments is only as good as the underlying data. A bad place is when data is dirty, full of errors, and full of null values. In this case, the analyst or data scientist needs to decide how they want to impute or clean this messy data. This is not the value-added work that the analyst or data scientist is either trained for or should be spending their time doing.
AI and Machine Learning models. You might think of models as consumers, but remember that a data model serves humans and machines. These models are critical automated consumers that require clean, reliable, and well-structured data ("features") to make predictions, classifications, or generate content. The performance of a customer-facing recommendation engine, LLM, or an internal fraud detection system depends entirely on the quality of the data it consumes.
Your primary job is to serve your internal consumers. They rely on you, and you rely on them. You must be empathetic, attentive, and focused on the needs of your co-workers. Your data model needs to be believable enough that people trust it, and performant and straightforward enough that people will use it. A data model that doesn’t answer questions or is too slow, confusing, or limited will have abysmal adoption, no matter how elegant the design. Modeling for internal consumers is about clarity, accessibility, and alignment with the goals and decisions they’re accountable for.
External Consumers
”The purpose of a business is to create and keep a customer.” - Peter Drucker
For some technicians, there’s the belief that their work stops outside of their team or company. Especially for people operating in Enterpriseland, this is especially true. Ultimately, every organization serves someone or something in the greater world. The data you provide to internal consumers should, indirectly, have an impact on the end customer for your organization.
If you’re in Productland, your data model will be directly consumed by external users, outside of your organization. Let’s call them customers. Customers are the ultimate consumers, interacting with the output of your data models through product features like personalization, search results, recommendations, etc.
If you’re not in Productland, your data model might still be consumed by non-customer external consumers. These might be business partners, suppliers, regulators, auditors, or anyone else who needs access to your data to do their jobs. These external stakeholders consume data from your systems via APIs, file sharing, etc.
Depending on the external stakeholder, your data model will need to meet varying degrees of precision and requirements. Much of this depends on the risk involved. For instance, if you’re selling shoelaces and you share an Excel report with a supplier about last week’s sales (you laugh, but this is extremely common), if the report is off by a few units here and there, it’s probably not a big deal. Any discrepancies in quantity will balance out over time through sales. On the other hand, if you’re providing data for regulatory purposes (e.g., SOX, GDPR, etc), the risk is high if your data doesn’t meet the strict requirements of the regulator. The public might also be impacted by your data model, in the form of biased algorithms and data being used for things like lending, hiring, or policing. Know the game you’re playing. What are the ethical, privacy, or legal consequences of your data model?
Your role is Sales. Not hard selling, but you need to persuade leadership and colleagues why taking extra care in the data model matters, balancing the investment versus the risks of getting it wrong. You must advocate for ethical, compliant, and fair data practices, even when they add cost or slow delivery. Selling the “why” is essential to prevent reputational, legal, and ethical disasters.
Your Support Crew
Data modelers don’t work in a vacuum, or at least shouldn’t. Inevitably, you’ll have a support crew around you who will support your data model in various ways. These might be software or data engineers, DBAs, or IT teams. Or, if your company lacks resources, you might be your own support crew.
Here, I’m going to focus on supporting the physical data model, as this is what most internal and external consumers encounter. While the conceptual and logical models remain essential, the physical model is what most people depend upon to do their jobs.
A data model is useless if nobody can use it. Support focuses on ensuring the model’s accessibility, maintainability, and integration with other systems. Engineers and DBAs will keep the systems performant and scalable, integrate the model into applications and pipelines, and monitor the reliability, cost, and security.
All of these activities support the work you’re doing, so make sure your supporters are your allies. Here, you step fully into the Practitioner role. You’ll get respect by being technical enough not to be a bottleneck or nuisance. Win over this group and your model will stand the test of time. I’ve seen data modelers ignore the input from their support team. For instance, the physical model might be overly complicated, impossible to maintain, or too costly to run. Ignore your support group at your peril. If you do so, your model will likely collapse under its own weight or wither from obscurity. Instead, bring them in early, listen to their concerns, and bake these into your model, and co-design where possible. Remember, data modeling is a full-contact sport. Collaboration, especially with the people directly supporting you, is how you build a resilient, production-grade data model.
Everyone Else
Then there’s everyone else. Beyond the dedicated few, a vast majority of individuals remain largely unfamiliar with the craft or importance of data modeling. Frankly, many do not perceive it as a pressing concern. Put more bluntly, most people don’t know or care about data modeling. Your work may impact them, but discussing data modeling with them will likely elicit blank stares and possibly even annoyance. When communicating data modeling, gauge the room's temperature to ensure you’re speaking with people who understand the subject matter.
A classic trap I see technicians run into is equating their role to that of the larger organization. I once overheard a coworker claiming that most startups fail because they don’t adopt functional programming. I just shook my head at this person’s lack of awareness of how business works. Software engineers might view things through a systems lens, some data people think every solution to the company is to be “data-driven,” and so on. Remember, your world isn’t the bigger world. Know the difference.
You might take on the Sales role here, with a strong emphasis on might. More likely, it’s none of the three roles at all, and your role is simply to know whether to be quiet. Before diving into technical specifics, gauge others’ understanding and interest in the subject matter. Tailor your communication approach to resonate with their level of comprehension, focusing on the practical implications and benefits rather than the underlying technical complexities. A successful data modeler understands not only the data itself but also the diverse perspectives and priorities of the stakeholders they serve, adapting their message to ensure clarity, relevance, and ultimately, buy-in.
It is embarrassingly common to see this mindset out in the wild:
“A classic trap I see technicians run into is equating their role to that of the larger organization… Remember, your world isn’t the bigger world. Know the difference.”
Thanks for taking the time to call it out. The concept itself might make for a solid article and/or podcast episode.