
Semantics, Ontology, and Taxonomy, and Metadata – Foundations for Meaning in Data Modeling

Here it is - the draft of the latest chapter on meaning in data modeling. I give some building blocks that we’ll use throughout this book, as well as Book 2 (applied data modeling). I also take a stab at speculating the future of these building blocks as AI agents become pervasive. Will AI have a role in helping us create and manage more meaningful data? I guess you’ll have to read to get my thoughts.
Please leave a comment if you feel I’ve missed something important. And if there are grammatical or similar errors, please leave a note here.
Thanks,
Joe1
When I first started working on this book a couple of years ago, the discussion of meaning and semantics in data modeling was very sparse. But with the entire world’s focus on AI right now, there is fresh attention on these areas. A discussion of data modeling in this new context (no pun intended) is incomplete without covering meaning, semantics, and knowledge.
This chapter serves as a primer on capturing meaning through semantics, ontologies, taxonomies, and metadata. It is not meant to be a comprehensive and detailed guide to these topics, each of which fills entire books. This chapter forms the basis for learning how to apply these approaches, which we’ll cover throughout this series.
Why Meaning Is the Missing Link in Data Modeling
There’s a silent assumption in data modeling that data has meaning. The big question is, what does it mean for whom? Exactly what do we mean by meaning?
I’m not going to get overly philosophical or pedantic. But many problems arise from ignored semantics. These might take the form of integration failures, mismatched assumptions, or scattered definitions. Any of these can obviously create chaos in the data model.
There’s also a macro trend occurring in the data. Models are just about the structure of data. Again, the popularity of AI, especially large language models, is shifting the focus from “structure only” to “structure plus semantics”.
What Do We Mean by Meaning?
What exactly do we mean by “meaning”? This is a question that still comes up, and since this is not a philosophy book and we’re trying to keep things practical, I’ll give a caveman definition of meaning. Meaning is what something is intended to signify or express.
There’s meaning to you. Then there’s meaning to me. Where our individual meanings overlap, we create shared meaning, and that’s the space where data modeling lives.
Classically, data modelers like to point out that very few companies have a single definition for concepts like “Customer.” There might be several varieties of a Customer - when did they last order? How much did they order? What level of time and quantity counts as a Customer? And by the way, what is an Order? If the Customer requested a free sample 10 years ago, is that person a Customer, and was that actually an Order? This is where the hard work of data modeling starts. This is the fun and hairy part of data modeling. Meaning can vary by context.
This ambiguity of meaning in a business context stands in stark contrast to other fields that demand objective, universal truths. In some fields, meaning is (usually) concrete and unambiguous.
My background is in mathematics, and I was subjected to endless lemmas and theorems that I had to prove both forward and backward. Simple things we take for granted, like addition, have rigorous mathematical proofs. Addition is unambiguous. Then there’s the scientific method, an agreed-upon practice for testing and validating our hypotheses. If enough people test out a hypothesis and reach the same conclusion, that hypothesis is accepted as “fact.” Of course, science always leaves the door open to the possibility that something will be invalidated. In mathematics, the statement 2+2=4 is an objective truth that doesn’t change based on context or opinion. In chemistry, the molecular structure of water is always H2O. And in my personal life, as an avid rock climber, despite some people arguing otherwise, I can assure you that gravity is very real. Hence, I always tie into a rope or fall onto a crash pad.
I could go on, but my point is that meaning is mostly subjective, sometimes objective. It all depends on the context and the thing to which you’re ascribing meaning. Because data models are seldom used by only one person, but instead a group of people, your job as a data modeler is to capture and represent the shared meaning of what you’re trying to convey in data. This shared meaning creates a common understanding of concepts, vocabulary, and related terms across the organization. It also facilitates a shared understanding between organizations, particularly in the context of standards.
I know philosophers will probably shoot down what I’ve written. That’s ok, since this isn’t a chapter on philosophy. The main takeaway is that your job is to capture this messy, contextual, but vital meaning in a way that it can be collectively agreed upon and understood. This is the essence of data modeling, whether for humans or machines. Meaning in data modeling lives in that messy middle ground, where it’s subjective enough to need context, and objective enough to require shared rules.
Semantics in Data Modeling: What Do You Mean?
If meaning is what we agree something is, semantics is how we describe and preserve that agreement in language. Semantics is the heart of data modeling. While traditional modeling has focused on technical structure, it often overlooks a key component: shared understanding. Creating a common interpretation of data is the key to solving communication bottlenecks between people and, increasingly, between people and machines. With the rise of AI as both a consumer and generator of data, semantics is no longer a second-class citizen. Semantics ensures that the real-world meaning of data and the relationships among different data elements are consistently captured and understood by people and machines.
Semantics introduces a common vocabulary. For instance, instead of just having a “cust_id” field, a semantic model would define what a “customer” is, what their attributes are (e.g., name, address), and how they relate to other concepts like “orders” and “products.” This clarity is crucial for business users who need to understand the data without getting bogged down in technical jargon.
As you learn about semantics, you might run into terms like controlled vocabulary and thesaurus. A controlled vocabulary is a pre-defined, authorized list of terms used to ensure that data is labeled and categorized consistently. You’d use a controlled vocabulary to control synonyms and reduce ambiguity. For instance, the term “Data Engineer” is a designated concept that maps to synonyms such as “ETL Developer” or “Data Platform Engineer.” We further address ambiguity by clarifying terms with multiple meanings. The term “platform” is commonly annoying in engineering circles and means different things to different people, so that we might define it as “cloud platform” or “data platform.”
A thesaurus is a more advanced type of controlled vocabulary. It doesn’t just list terms, but also defines the semantic relationships between them. A term might have a broad or narrow hierarchical relationship, such as Data (broad term) -> Data Modeling (narrow term). Or, terms might be related to each other, like Data Modeling (Related Term) <-> Data Governance. These concepts are not hierarchically linked. Instead, they are closely related and are often discussed together. Finally, terms might be equivalent, where one term is used in place of another, such as MLOps (Use) -> ML Operations (Used For). This connects synonyms to the single preferred term.
This becomes more complicated when organizations have multiple systems of record. For example, one system might use “client” while another uses “customer.” Are these the same thing? This is a direct application of the tools we just discussed: a controlled vocabulary defines “customer” as the single preferred term, and a thesaurus maps “client” to it as an equivalent concept. This exercise of mapping varying definitions to a single one might seem familiar if you come from a traditional data modeling background. And that’s a good thing. We’re trying to remove ambiguity and create a shared vocabulary of what something means.
Disambiguating “client” and “customer” is hard enough in the context of mapping database keys like “client_id” and “customer_id”, and their associated attributes. This gets even harder when we move from SQL queries to natural language prompts. Extend this example to an LLM that might get a prompt like “show me the top clients for region X” and “show me the top customers for region X.” Same region, but are the client and customer the same thing? This is where correctly mapped semantics matter more than ever. As you’ll see, there’s a lot of work being done right now to give semantics structure so AI can locate the best data to use, whether structured or unstructured.
Beyond defining core business concepts like ‘customer,’ semantics also clarifies the meaning of individual attributes. This is often accomplished through rich metadata that travels with the data itself. A semantic model might include metadata (which we’ll learn more about later in this chapter) as labels to help capture the data model’s essence and meaning. In practice, this could mean tagging a data field with its units (e.g., location and timestamps of an image) or specifying that “Status” is an enum type with allowed values defined by business rules. By doing so, the data model carries the business context. It’s not just raw data, but data (and data about data) with meaning.
Once we define what things mean, we need a way to organize them, which is where taxonomies come in.
Taxonomies: Organizing Concepts into Hierarchies
When we model data, we often want to organize concepts and relationships into a hierarchical structure. A simple example anyone can understand is a parent-child hierarchy, where the top-level is the parent and any dependencies are children. Let’s look at this in the literal parent-child sense, with a parent with two children. This hierarchical parent-child relationship is a taxonomy.
You can think of a taxonomy as an organized “tree” of related concepts, moving from broad categories to more specific ones. Taxonomies fit rather nicely into our e-commerce example since a product catalog is a taxonomy. You might have a parent category called All Products, with subcategories such as Electronics, which in turn have subcategories like Phones, Computers, Gaming, Drones, etc.
All Products
Electronics
Phones
Computers
Gaming
Drones
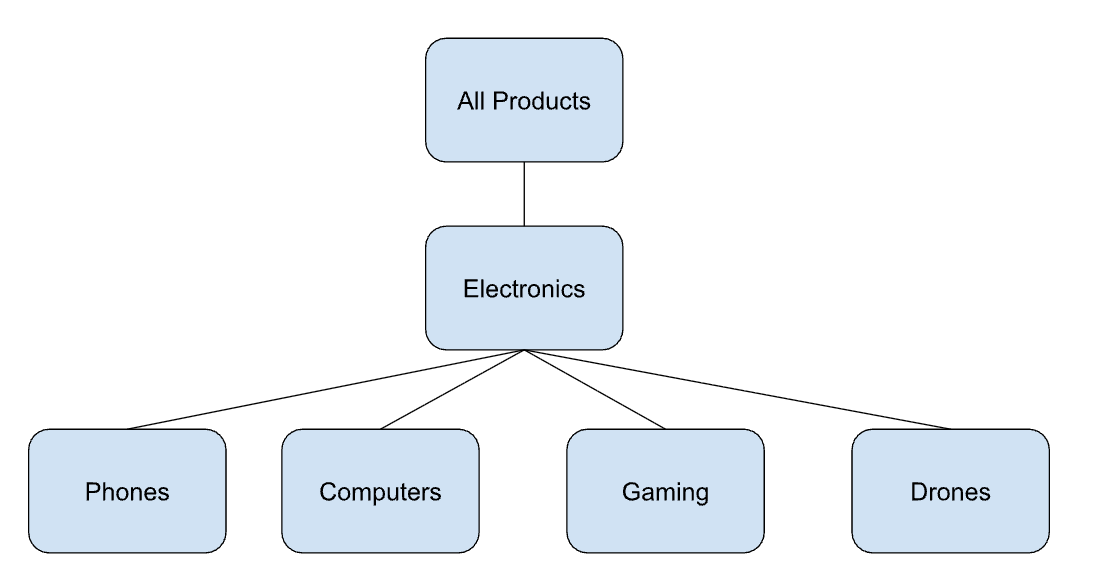
Here, the hierarchy’s structure is precise. Navigating this hierarchy is intuitive and straightforward to the user. The hierarchical ordering of things matters in a taxonomy. All Products is a parent category of Phones; the reverse isn’t true; Phones won’t be a parent category of All Products. Using relationship nomenclature, we can say that a Phone is an Electronic device, and Electronics is a subset of All Products.
You might wonder why we go through the trouble of organizing things in taxonomies. Why not just throw all the data together and see what happens? Back to the product catalog example, if you were to navigate an e-commerce site with random products and had no sense of how they’re organized when you search for a product, this could be a very frustrating experience. Assuming this e-commerce site doesn’t have good search capability, you would very likely leave for a site with a better user experience. Taxonomies organize things in a way that makes sense. They logically group things. Without taxonomies, you’re left navigating a bunch of random stuff without a map.
Beyond improving the user experience, taxonomies provide two critical data management benefits: standardizing terms and improving data governance.
First, a taxonomy helps with the age-old problem of people in the business using different terms for the same concepts. Without a taxonomy, your US sales data might use Region: “West”, while your marketing data uses Area: “Pacific”, and finance uses Territory: “CA, OR, WA”. That’s not ideal, as this can lead to a lot of crossed wires and misunderstandings. Is the Pacific region composed of “CA, OR, WA”? What about “AK” and “HI”? With a taxonomy, you create a single “Geography” taxonomy that everyone must use, clearly stating that “Pacific” is a subcategory of “West.” This enables consistent data integration and analysis.
Second, taxonomies improve data governance and quality. By defining an “official” set of categories, you can enforce constraints that prevent users from entering “junk” data. For example, you can require that a Product_Category field must contain one of the approved values, such as those in the Electronics taxonomy above. If a user tries to enter a food item, such as “Sandwich,” as a subcategory of Electronics, this would be a violation of what’s allowed. The taxonomy obviously and dramatically improves data quality and consistency.
This brings up a final question: when is a taxonomy not enough? Semantics and taxonomies by themselves are helpful, but what about making it easy for them to work with machines? The next step is to assemble them into a formal framework that allows machines not just to read the data, but to reason over it.
Ontologies: Giving Flexible Structure to Meaning
“An ontology is an explicit specification of a conceptualization.” - Tom Gruber, A Translation Approach to Portable Ontology Specifications
Suppose semantics concerns the meaning of concepts, words, and relationships, and taxonomies organize these hierarchically. In that case, an ontology captures the informal meaning and expresses it in a formal semantic model for human and machine interpretability. Ontologies define concepts (Customer, Product, Order), specify their relationships (a Customer places an Order), and add rules and constraints (every Order must have at least one Product).
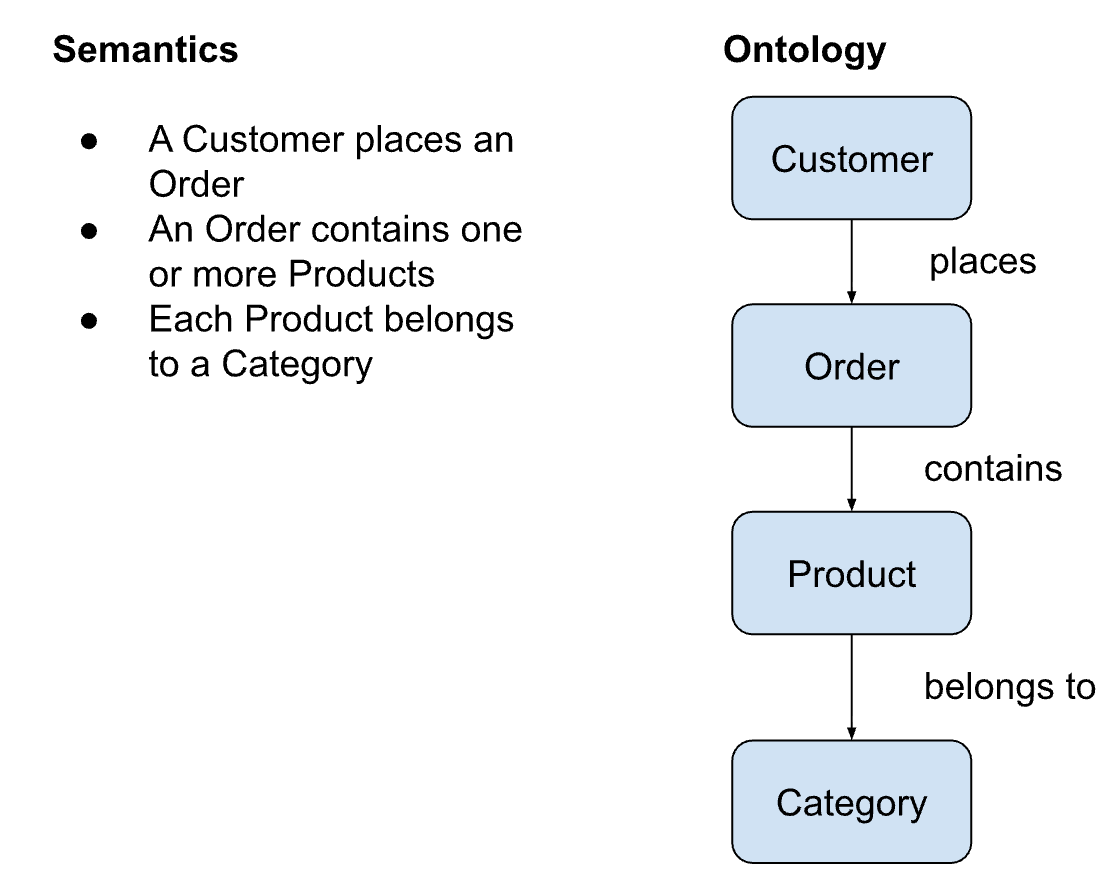
So how do we formalize this? We know that “a Customer places an Order for a Product.” This is a self-evident concept in plain language. But this informal understanding isn’t something a machine can use.
To make it machine-readable, an ontology represents these concepts, relationships, and constraints in a logic-based language like the Resource Description Framework (RDF) or the Web Ontology Language (OWL). Here, we’ll use a simplified OWL notation to demonstrate this translation.
Prefix: : <http://example.org/shop#>
Prefix: owl: <http://www.w3.org/2002/07/owl#>
Prefix: xsd: <http://www.w3.org/2001/XMLSchema#>
Ontology: <http://example.org/shop>
### Classes
Class: :Person
Class: :Customer
SubClassOf: :Person
Class: :ProductKeep reading with a 7-day free trial
Subscribe to Practical Data Modeling to keep reading this post and get 7 days of free access to the full post archives.