
The Relational Model, Part 3
Some Thoughts and Considerations

This is the final part of the three-part relational modeling series. Here are links to Part 1 and Part 2.
Enjoy,
Joe
If you work with data (tabular or otherwise), the legacy of the relational model looms large. Because it’s been around for several decades, it’s widely taught and adopted in organizations of all sizes. Despite its ubiquity, both as a practice and popular type of database, I sense a difference between adoption in the past and the current state of affairs. These days, I find the relational model misunderstood, and it feels like a dying art and science. This book aims to bring data modeling approaches like the relational model back into vogue.
Here’s a summary of my thoughts on the relational model. While not exhaustive, it should give you some things to consider.
Relational Modeling is a THINKING Exercise
We just reviewed the key parts of the relational model. You’re probably tempted to try it out and wonder how to start. Too often, data modeling starts at the physical modeling level. You could certainly create a bunch of tables using SQL CREATE statements. Or you could shove a bunch of data into a table. But I suggest stepping back and understanding your data from first principles. What are the entities, attributes, and their relationships? What are the identifiers (keys) of a dataset? How are attributes dependent on the key? What happens if I update a row of a table? These questions force you to think about how data is represented and structured.
Relational modeling - and data modeling in general - is, first and foremost, a thinking exercise. You’re mapping the representation of business concepts and vocabulary to data. You might call this the conceptual or logical level of data modeling. Whatever you want to call it, treat the relational model as a thinking exercise about the intersection of your business and data, not simply a rote activity to create a database schema.
Criticisms of the Relational Model
Here are some common criticisms I hear of the relational model.
It feels like a “big design up front” or “waterfall.”
Creating and maintaining the model is too much work.
The number of tables it creates requires a lot of joins, which hurts performance.
It doesn’t scale to large amounts of data.
It doesn’t support streaming workloads.
Unstructured and semistructured data isn’t supported.
I could go on, but you get the idea. The themes of concern range from the relational model being overly complicated and rigid to outdated. Sometimes, these are fair criticisms, and technology has evolved to address situations where the relational model simply can’t keep up performance-wise, such as massive NoSQL databases serving billions or trillions of requests a day or event stream processing engines handling millions of requests per second.
Most of the time, people are nowhere near handling data on the scale I just described. A plain old RDBMS will work just fine in most cases. Sadly, people will read the blogs of Big Tech companies and believe that Big Tech solutions are precisely what’s needed. This technology-first approach guarantees you’ll start and end with physical data modeling. The result is a data model that performs well for a specific system, at least for a while. But because you didn’t take the time to think about your data from first principles, you’re inevitably causing problems for yourself. Your “data model” will likely be disconnected from the business in which it operates. If you need to migrate your data to the next flavor-of-the-month database, now you have the double-whammy problem of porting poorly-thought business logic and highly optimized query and storage logic. I’ve seen this happen all the time, often with excruciating results.
This highlights a big issue I see regarding criticisms of the relational model. Taking a step back, it’s tempting to consider the physical systems where data is stored and queried without considering what it means and represents. The relational model offers a mathematical lens through which we can think about and work with data. As I said earlier, the relational model is a thinking exercise. The thinking process of removing redundancies and side effects is still warranted, even in situations where you may not use tables. If you understand the relational model, you have a good foundation to critique its shortcomings and move beyond its limitations. But don’t ignore data modeling just because it’s viewed as complicated or extra work. You’ll cause yourself unnecessary harm, unintentionally reinvent the wheel, or make things worse.
Relational Model != Relational Database
I find people who think they're also doing relational modeling because they use a relational database. The relational model shouldn’t be confused with the relational database. Just because you use a relational database doesn’t directly imply your data is normalized. Cramming data into a relational database does not make a relational model.
Quite the contrary, at least in my experience. It’s crazy how many applications I see running on an RDBMS like Postgres, but relational modeling isn’t being done as well as it could. It’s not uncommon to see data that’s in 1NF (I joke it’s 0.5NF); JSON fields galore. Especially with the prevalence of object-relational mappers (ORM), writing code that adds new fields to tables is easy while ignoring the data behind the scenes. The application developers often complain of update and delete side effects, data sprawl, and poor-performing queries. As data grows, so do the RDBMS problems. It doesn’t get better with time.
The issue comes back to Codd’s initial motivation for the relational model—data independence. When you think about the relational model, you must decouple it from the physical implementation. Under data independence, the data model logic and the application it serves are separate things. If you’re using an RDBMS, start with the relational model and fight like hell to keep it that way.
Is the Relational Model Only for Applications?
The relational model is most commonly associated with transactional workloads and applications. As you learned earlier, it was created to create data independence between the data model and application workloads. I lumped in the relational model with application and transactional workloads simply because that’s its genesis. Also, highly normalized relational models aren’t used as much in other use cases like analytics. It is what it is. That said, nothing stops you from using the relational model outside of applications and transactional workloads.
The Relational Model and SQL
The relational model is sometimes used synonymously with SQL. It should be clear now that SQL allows things the relational model prohibits. For instance, SQL allows nulls and duplicate tuples. The relational model does not. This isn’t to dismiss SQL, as it’s had a very successful track record. When you use SQL, be aware of its shortcomings against the complete relational model.
The relational community has long resisted SQL and introduced alternatives like the Tutorial D language, which is relationally complete. However, given SQL’s prevalence in nearly every database, its long history, and widespread adoption among practitioners, the community seems to have begrudgingly accepted SQL’s place in the universe.
Denormalized and Unnormalized Models
We discussed normalization and lossless decomposition. Some terms you might hear are “denormalized” and “unnormalized.” I often find these terms misunderstood, so let’s define them and then understand where these approaches usually appear.
Denormalization means adding additional redundancy to a normalized model. Denormalization is an approach taken when normalization starts to show problems, such as table joins at a massive scale or query complexity. This indicates you’re starting with normalized data. Without the knowledge of normalization, you won’t know how to denormalize, and you’ll have a mess on your hands.
What about unnormalized data? Unnormalized data is raw data not adequately structured for querying in a table. For example, JSON is a ubiquitous data format called the “data of the web.” Is this JSON normalized or unnormalized? This is tricky because normalization isn’t strictly followed for semi-structured data like JSON. However, an everyday use case is converting JSON into tabular form.

The data is JSON compliant, but if you tried to put it in a table (not as a JSON type), you’d need to manage those pesky Item and Quantity keys. Let’s translate this into a “dumb” table1, where we map each column and row directly from JSON into a single table row.
In almost every database, the Item and Quantity columns will need to have unique names, since duplicate column names cannot exist in the same table.

However, in spreadsheets and some dataframes that don’t enforce column name uniqueness, you might get this confusing mess where the Item and Quantity column names are duplicated. If you query the data, which Item is the one you’re querying?
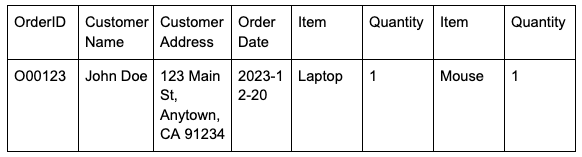
This table is…ok. But it’s pretty useless if you want to do anything other than look at it. You can only edit the row if you need to update the item or quantity. It’s also impossible to aggregate quantities decently, so let’s improve the table.
To normalize this data, you’d need to create a table with Item and Quantity columns and a separate row for “Laptop” and “Mouse.” For simplicity's sake, I’m skipping adding other information (item and customer IDs).

This table needs further normalization and some proper keys, but you get the idea of converting JSON to a table. To convert a table to JSON, you will identify a standalone key and what goes into an array.
Remember that the relational model doesn't strictly apply to semi-structured formats like JSON. Normalization deals with relations (tables) and attributes (columns), while JSON represents data in a hierarchical structure of objects and arrays. Still, you can use relational concepts - namely sets - to ensure your data doesn’t have redundancies or update/delete anomalies. Especially with semi-structured data where the schema is highly flexible, it’s more important to think about your data and pay attention precisely because it’s super easy to introduce duplicates and other erroneous data. Highly flexible schemas are like a bear trap - very easy to get into and insanely painful to get out of.
But remember—while normalization provides these benefits, we sometimes deliberately denormalize for performance. The key is understanding the trade-offs involved.
The next time you design a database, start with proper normalization. You can always denormalize later, but starting with a clean, normalized design makes managing future changes much more manageable.
This table has a lot of issues. Ramona C Truta brings up that the Item and Quantity columns should be denoted by Item X, QuantityX and Item Y, QuantityY. This is a better way to make the “dumb” table less dumb. Most databases won’t let you have the same column names in the same table, but a few allow this. You’ll also find this sort of column layout in spreadsheets and some types of dataframes, where there might be zero enforcement for unique column names.
Hi,
As in many other times I can only agree with most of the statements. It’s more of a “this is how things are done and it’s hard to believe people do it otherwise”.
I’d like to add one thought or a hint maybe, I tend to be strict to 3NF when creating an application where I have all the CRUD coded and supported with an UI (with some MVC or Flux architecture pattern). But when I’m in analytics and reporting world with code first (SQL, Python etc.) access to data plus visualization tools, I tend to allow myself a bit of denormalization which leads to data redundancy (like for example codes kept in some dictionary- I have the dictionary but I copy over the values to the entity, not just the relationship ) and needs more work in case of a change but makes the querying easier.
The classic “it depends” I guess.
Cheers
Thank you for the write up and interesting facts to revise the fundamentals of data modelling.
@JOE REIS are you planning to put down a thought how the data modelling be prevalent or need to be considered if the data lakehouse approach considered for Analytical work loads. Do we still consider relational modelling for datalake solutions as well ?
how about the real time streaming data and consumption pattern from those data sets ?